WEEK 7 HOMEWORK – SAMPLE SOLUTIONS
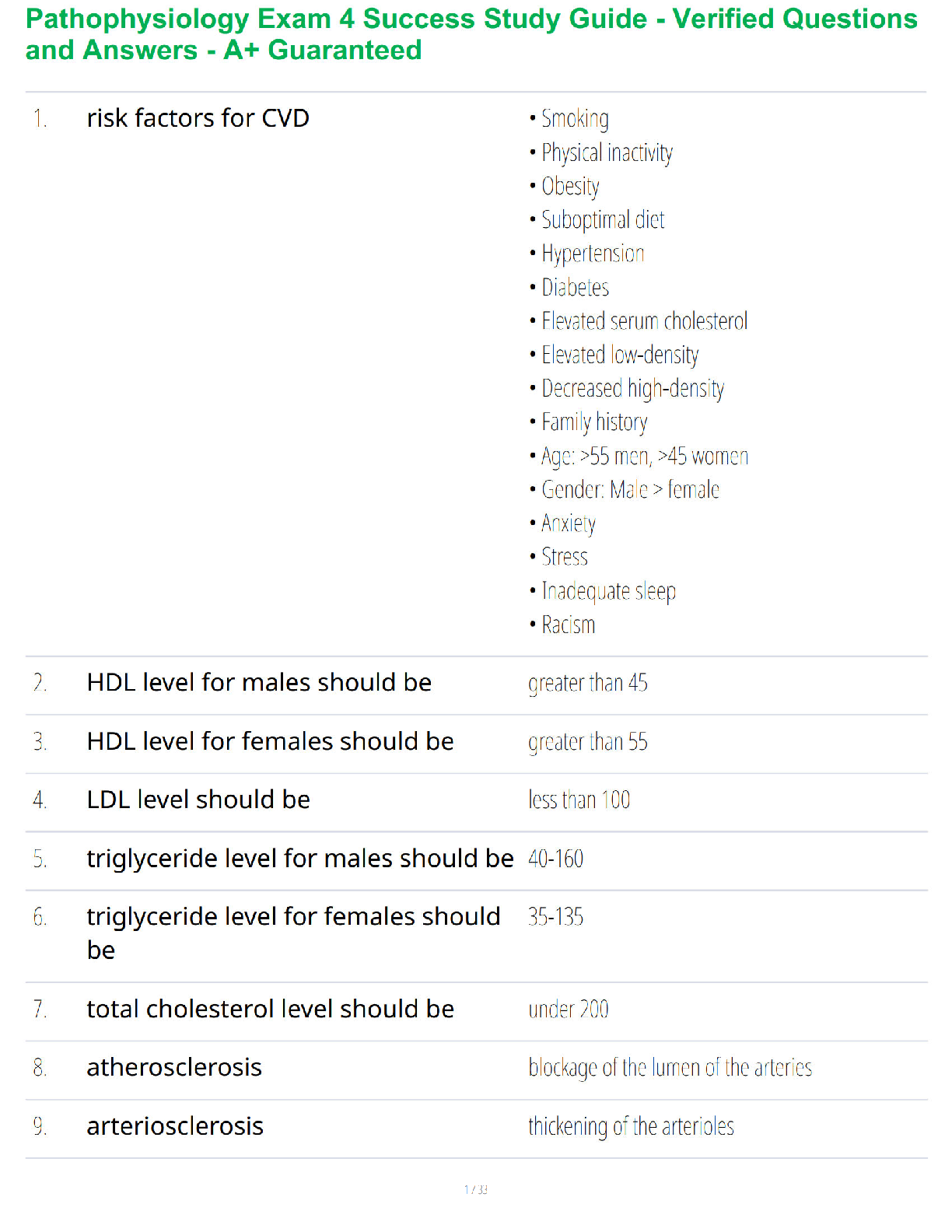
IMPORTANT NOTE
These homework solutions show multiple approaches and some optional extensions for most of the
questions in the assignment. You don’t need to submit all this in your
...
WEEK 7 HOMEWORK – SAMPLE SOLUTIONS
IMPORTANT NOTE
These homework solutions show multiple approaches and some optional extensions for most of the
questions in the assignment. You don’t need to submit all this in your assignments; they’re included here
just to help you learn more – because remember, the main goal of the homework assignments, and of
the entire course, is to help you learn as much as you can, and develop your analytics skills as much as
possible!
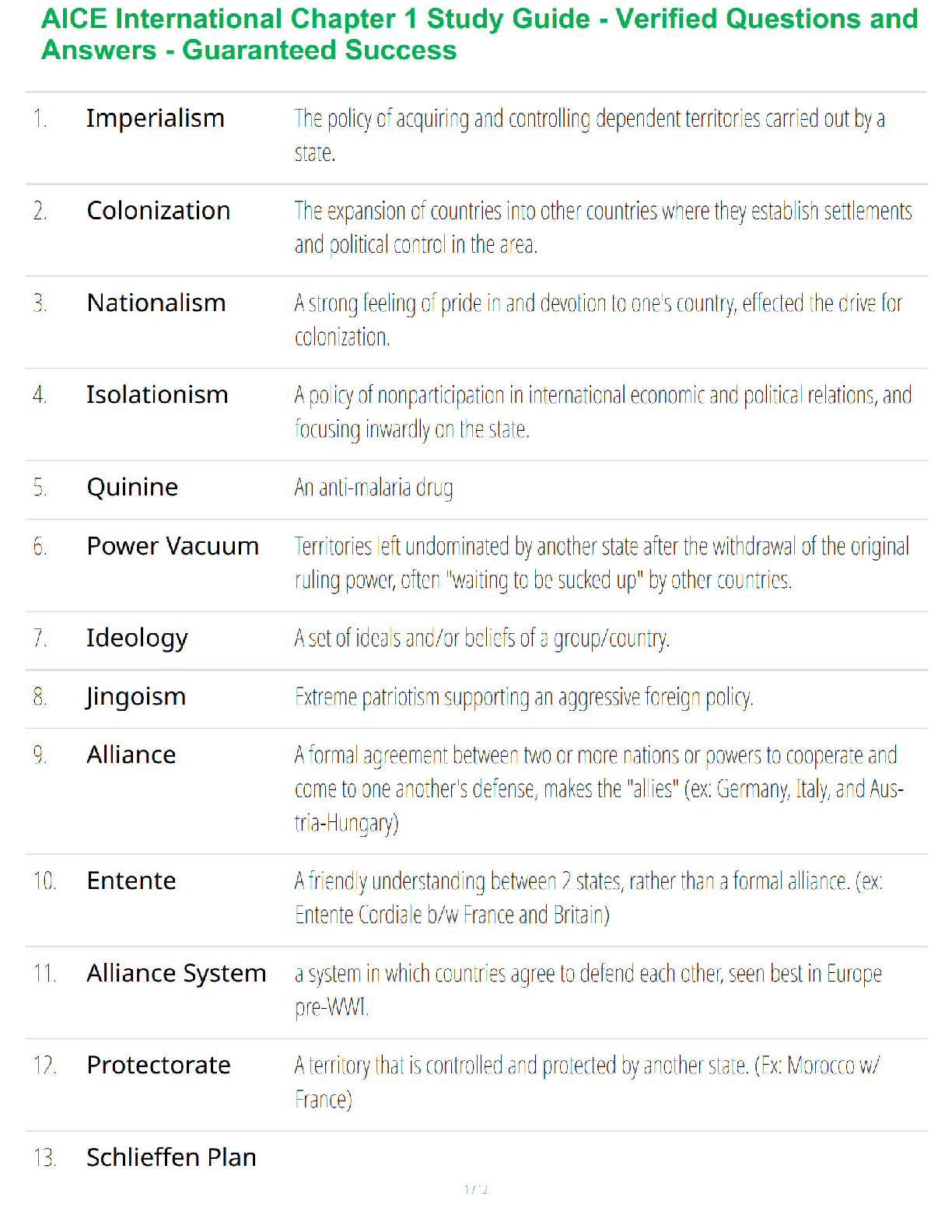
Question 1
Using the same crime data set as in Homework 5 Question 2, find the best model you can using (a) a
regression tree model, and (b) a random forest model. In R, you can use the tree package or the rpart
package, and the randomForest package. For each model, describe one or two qualitative takeaways
you get from analyzing the results (i.e., don’t just stop when you have a good model, but interpret it too).
(a) Regression Tree
Here’s one possible solution. Please note that a good solution doesn’t have to try all of the possibilities in
the code; they’re shown to help you learn, but they’re not necessary.
The file HW7-Q1a-fall.R shows how to build the regression tree. It shows two different approaches: one
using part of the data for training and part for testing, and one uses all of the data for training (because
we have only 47 data points). A visualization of one of the trees is below.
The tree in the figure (sometimes called a “dendro gram”) shows that four factors are used in branching:
Po1, Pop, NW, and LF. Notice that Pop is used in two places in the tree. Also notice that following the
rightmost branches down the tree, Po1 is used twice in the branching: once at the top, and then again
lower down.
It turns out that the model is overfit (see the R file). The R file shows a lot more possible models,
including pruning to smaller trees, using regressions for each leaf instead of averages, etc.
The models show that Po1 is the primary branching factor, and when Po1 < 7.65, we can build a
regression model with PCA that can account for about 30% of the variability. But for Po1 > 7.65, we
don’t have a good linear regression model; none of the factors are significant. This shows that we would
need to either try other types of models, or find new explanatory factors.
(b) Random Forest
The file HW7-Q1b-fall.R shows how to run a random forest model for this same problem. In the lessons,
we saw that the random forest process avoids some of the potential for overfitting. And (as the R code
shows) , cross-validation shows that it works better than the previous models we’ve found for this data
set.
The R code also shows the same sort of qualitative behavior as we saw from the regression tree model.
The random forest model too thinks that Po1 is the most important predictive factor for Crime. And, as
|
Po1 < 7.65
Pop < 22.5
LF < 0.5675
NW < 7.65
Pop < 21.5 Po1 < 9.65
500 700
800
1000 700
1000 2000
we saw from the regression tree, the random forest model gives better predictive quality for data points
where Po1 < 7.65 than it does for Po1 > 7.65. But unlike the regression tree, the random forest does
have predictive value even for Po1 > 7.65.
Question 2
Describe a situation or problem from your job, everyday life, current events, etc., for which a logistic
regression model would be appropriate. List some (up to 5) predictors that you might use.
Here’s one potential suggestion. In business-to-business sales and marketing, buying-propensity models
can be useful in ranking customers as high value or low value. A logistic regression model could be used
to predict the probability of a customer buying or not, or (using a threshold) to classify into yes or no
categories. Some of the predictors that could be used to develop such a model are:
1. Size of the customer in terms of revenue/year;
2. Average yearly spend (for the last 3 years) in the relevant product category;
3. The rating of the competitor(s) from where the customer currently buys the product (a market
leader would have a higher rating as compared to a new entrant);
4. The number of years associated with the customer (is the customer long-standing? Have they
bought from us for the last 5/10 years or is it a new relationship?);
5. Industry rankings for the product by various rating agencies (e.g., Gartner).
Using this model, sales teams can rationalize their efforts and concentrate their efforts on customers
that are more likely to buy, rather than going broad and losing focus while catering to all customers.
Question 3
1. Using the GermanCredit data set at http://archive.ics.uci.edu/ml/machine-learningdatabases/statlog/german / (description at
http://archive.ics.uci.edu/ml/datasets/Statlog+%28German+Credit+Data%29 ), use logistic
regression to find a good predictive model for whether credit applicants are good credit risks or
not. Show your model (factors used and their coefficients), the software output, and the quality
of fit. You can use the glm function in R. To get a logistic regression (logit) model on data where
the response is either zero or one, use family=binomial(link=”logit”) in your glm function call.
Here’s one possible solution. Please note that a good solution doesn’t have to try all of the possibilities in
the code; they’re shown to help you learn, but they’re not necessary.
The file HW7-Q3-fall.R shows a possible approach. The data includes a lot of categorical variables, and
for some of them, not all of the values are significant. So, as the R code shows, we have new variables
for each value of each categorical variable that’s significant.
Here’s a table of significant variables and their coefficients for the model (which has AIC = 673.5):
[Show More]



























![Preview of [SOLVED] EDCO 740 / EDCO740 Quiz 1 (LATES 2021/2022 Graded A)](https://scholarfriends.com/storage/EDCO_740_Quiz_1.png)



