Programming > QUESTIONS & ANSWERS > DATA MISC Homework 9: Central Limit Theorem | University of California, Berkeley (All)
DATA MISC Homework 9: Central Limit Theorem | University of California, Berkeley
Document Content and Description Below
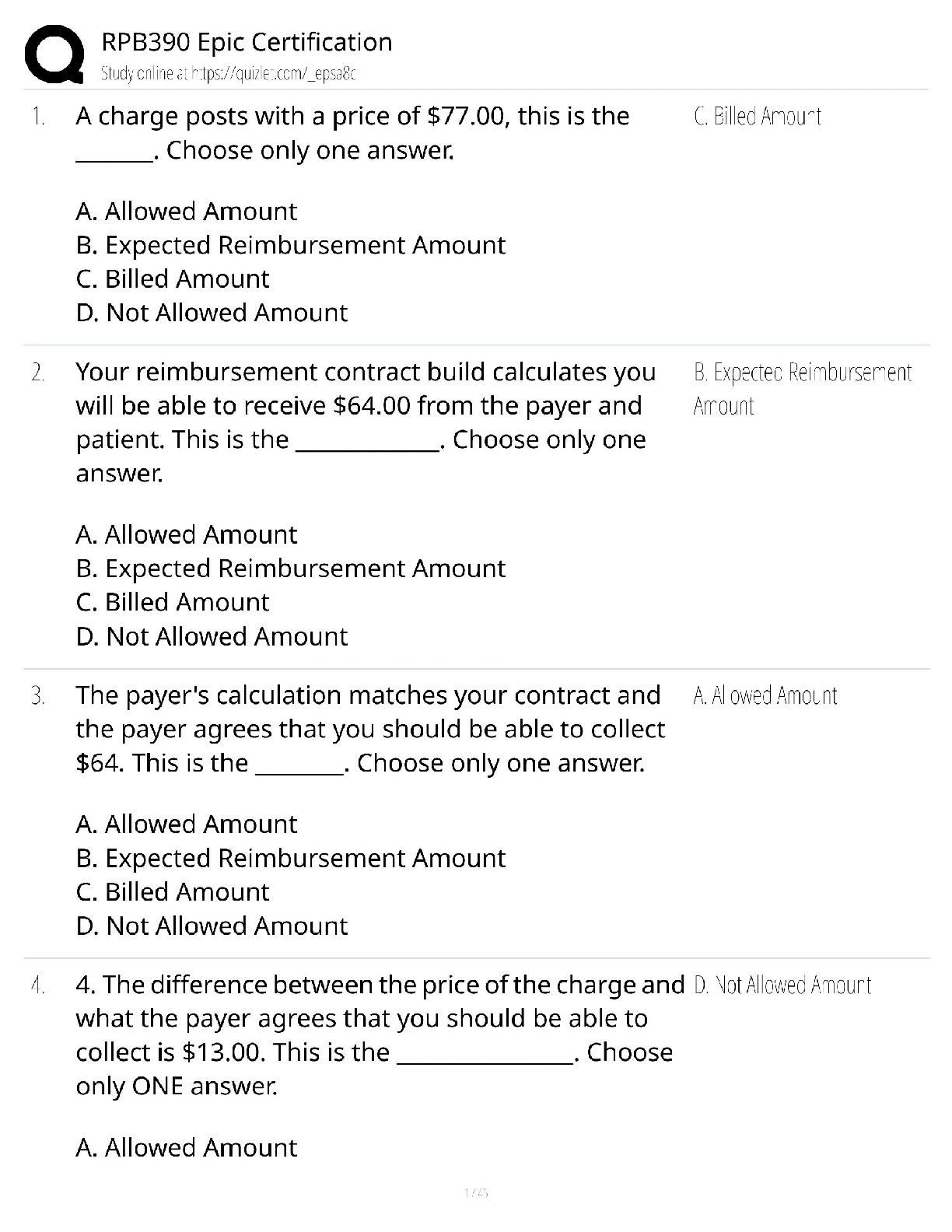
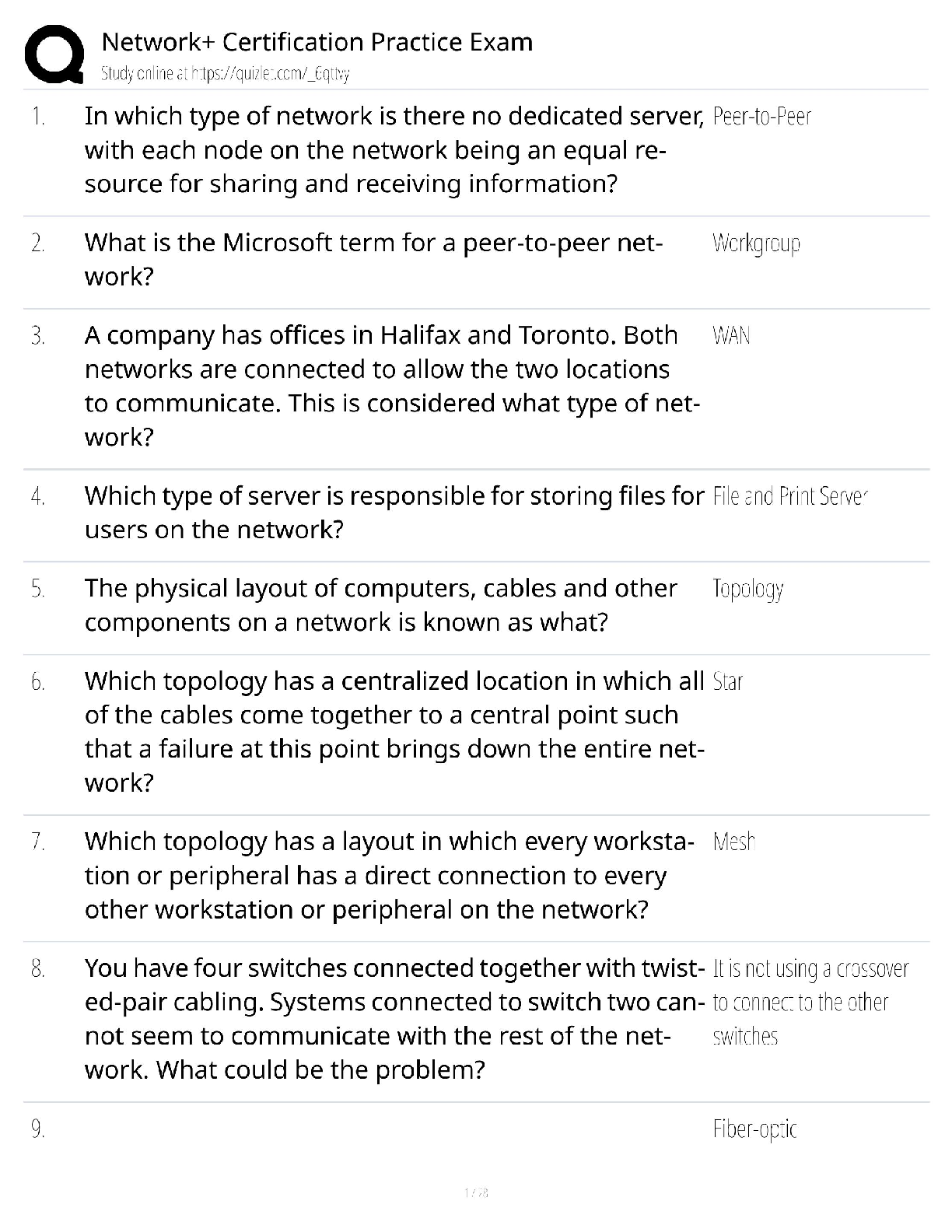
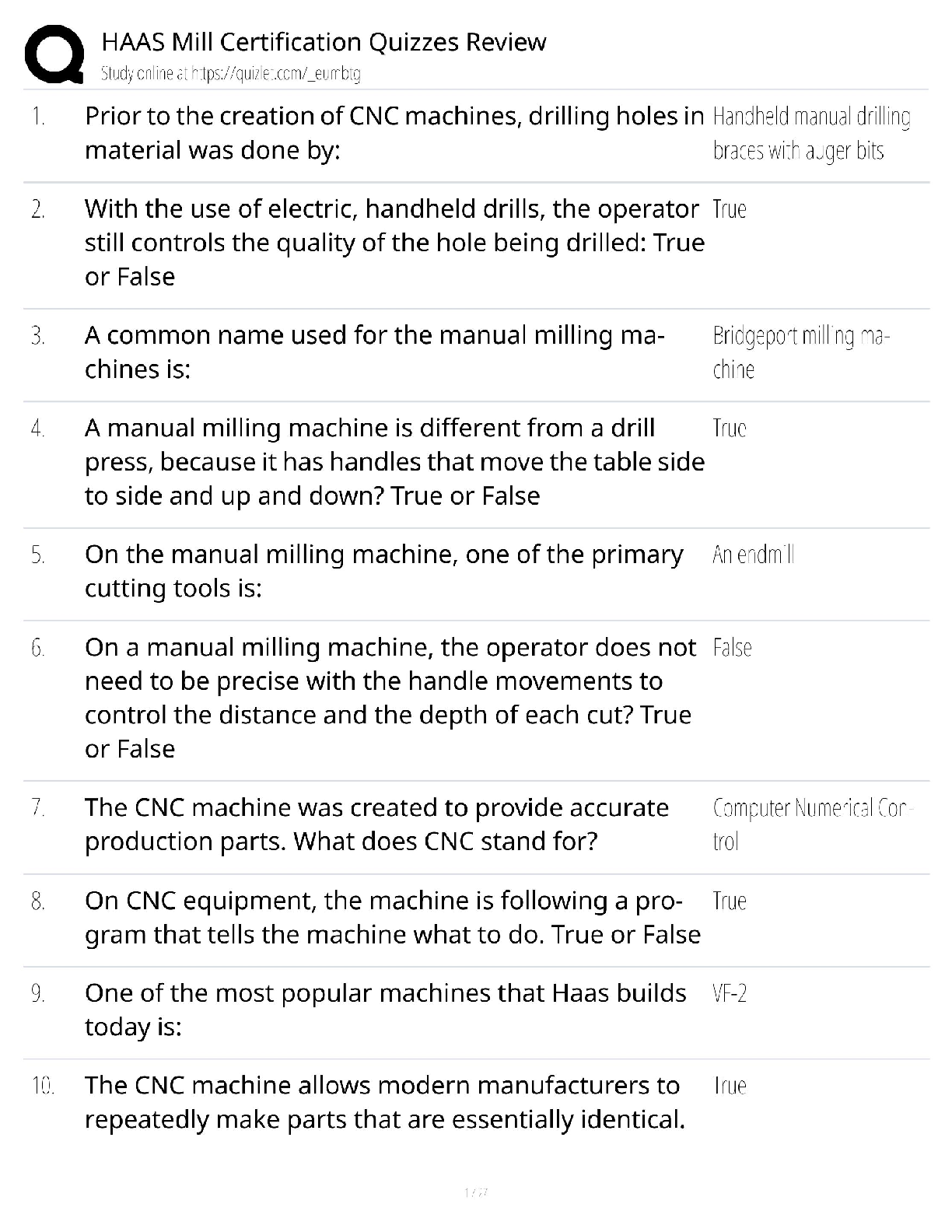
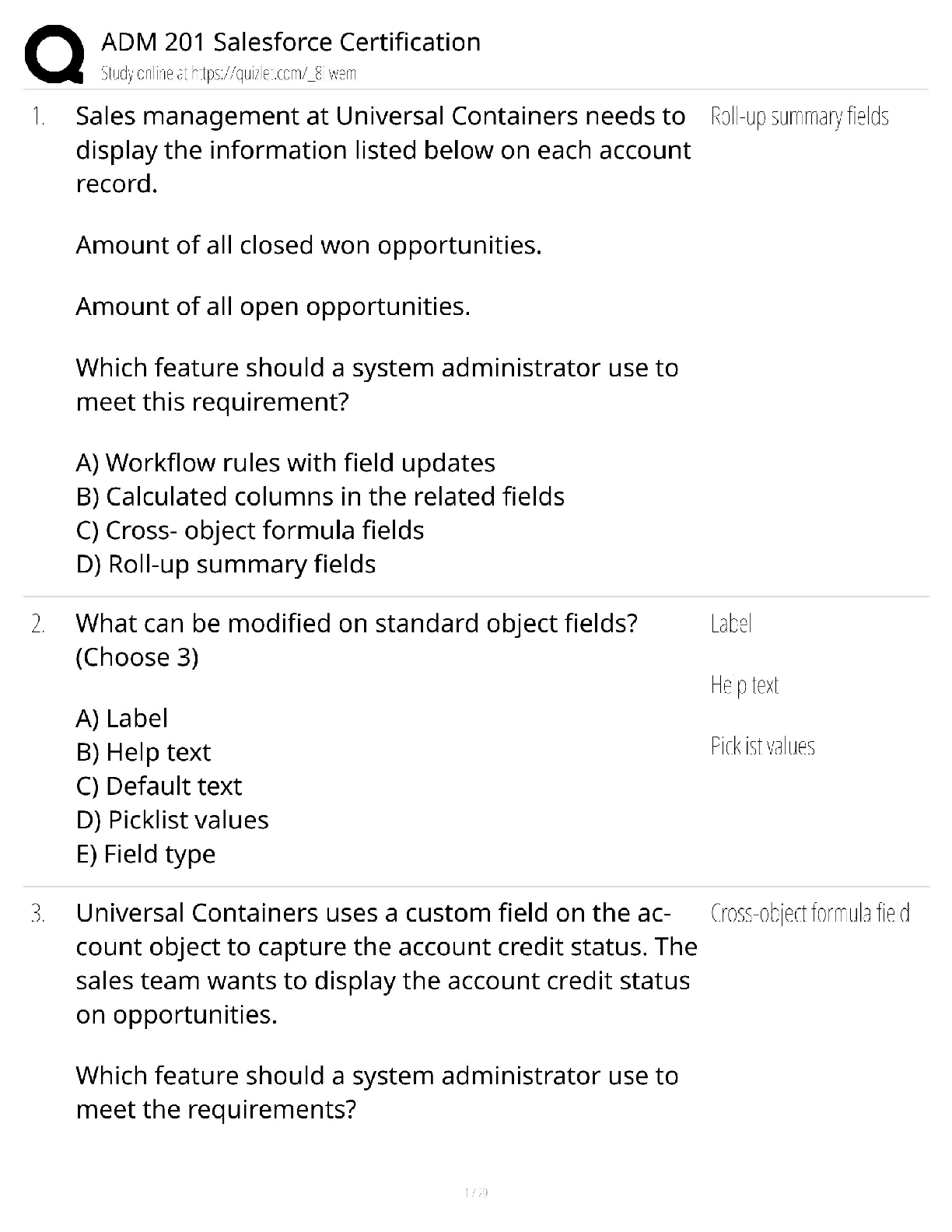
University of California, Berkeley DATA MISC 1 Homework 9: Central Limit Theorem Reading: * Why the mean matters Please complete this notebook by filling in the cells provided. Before you begi ... n, execute the following cell to load the provided tests. Each time you start your server, you will need to execute this cell again to load the tests. Homework 9 is due Thursday, 11/1 at 11:59pm. You will receive an early submission bonus point if you turn in your final submission by Wednesday, 10/31 at 11:59pm. Start early so that you can come to office hours if you’re stuck. Check the website for the office hours schedule. Late work will not be accepted as per the policies of this course. Directly sharing answers is not okay, but discussing problems with the course staff or with other students is encouraged. Refer to the policies page to learn more about how to learn cooperatively. For all problems that you must write our explanations and sentences for, you must provide your answer in the designated space. Moreover, throughout this homework and all future ones, please be sure to not re-assign variables throughout the notebook! For example, if you use max_temperature in your answer to one question, do not reassign it later on. In [1]: # Don't change this cell; just run it. import numpy as np from datascience import * # These lines do some fancy plotting magic. import matplotlib %matplotlib inline import matplotlib.pyplot as plt plt.style.use('fivethirtyeight') import warnings warnings.simplefilter('ignore', FutureWarning) from client.api.notebook import Notebook ok = Notebook('hw09.ok') _ = ok.auth(inline=True) ===================================================================== Assignment: Homework 9: Central Limit Theorem 1 OK, version v1.12.5 ===================================================================== Successfully logged in as [email protected] 1.1 1. The Bootstrap and The Normal Curve In this exercise, we will explore a dataset that includes the safety inspection scores for restaurants in the city of Austin, Texas. We will be interested in determining the average restaurant score for the city from a random sample of the scores; the average restaurant score is out of 100. We’ll compare two methods for computing a confidence interval for that quantity: the bootstrap resampling method, and an approximation based on the Central Limit Theorem. In [2]: # Just run this cell. pop_restaurants = Table.read_table('restaurant_inspection_scores.csv').drop(5,6) pop_restaurants Often it is impossible to find complete datasets like this. Imagine we instead had access only to a random sample of 100 restaurant inspections, called restaurant_sample. That table is created below. We are interested in using this sample to estimate the population mean. Question 3 Complete the function bootstrap_scores below. It should take no arguments. It should simulate drawing 5000 resamples from restaurant_sample and computing the mean restaurant score in each resample. It should return an array of those 5000 resample means. In [8]: def bootstrap_scores(): resampled_means = make_array() for i in range(5000): resampled_mean = np.mean(restaurant_sample.sample().column(3)) resampled_means = np.append(resampled_means, resampled_mean) return resampled_means resampled_means = bootstrap_scores() resampled_means Question 4 Compute a 95 percent confidence interval for the average restaurant score using the array resampled_means. In [11]: lower_bound = percentile(2.5, resampled_means) upper_bound = percentile(97.5, resampled_means) print("95% confidence interval for the average restaurant score, computed by bootstrap 95% confidence interval for the average restaurant score, computed by bootstrapping: ( 90.98 , 93.56 ) Question 5 Does the distribution of the resampled mean scores look normally distributed? State "yes" or "no" and describe in one sentence why you would expect that result. Yes, since the central limit theorem states that the distribution of sample averages tend to be normally distributed 6 Question 6 Does the distribution of the sampled scores look normally distributed? State "yes" or "no" and describe in one sentence why you should expect this result. Hint: Remember that we are no longer talking about the resampled means! No, since the sampled scores are distributed like the population scores , and the population scores are not normally distributed. For the last question, you’ll need to recall two facts. 1. If a group of numbers has a normal distribution, around 95% of them lie within 2 standard deviations of their mean. 2. The Central Limit Theorem tells us the quantitative relationship between the following: * the standard deviation of an array of numbers. * the standard deviation of an array of means of samples taken from those numbers. Question 7 Without referencing the array resampled_means or performing any new simulations, calculate an interval around the sample_mean that covers approximately 95% of the numbers in the resampled_means array. You may use the following values to compute your result, but you should not perform additional resampling - think about how you can use the CLT to accomplish this. In [12]: sample_mean = np.mean(restaurant_sample.column(3)) sample_sd = np.std(restaurant_sample.column(3)) sample_size = restaurant_sample.num_rows mean_sd = sample_sd / sample_size**0.5 lower_bound_normal = sample_mean - 2 * mean_sd upper_bound_normal = sample_mean + 2 * mean_sd print("95% confidence interval for the average restaurant score, computed by a normal 95% confidence interval for the average restaurant score, computed by a normal approximation: ( 90.9258714979737 , 93.6341285020263 ) This confidence interval should look very similar to the one you computed in Question 4. 1.2 2. Testing the Central Limit Theorem The Central Limit Theorem tells us that the probability distribution of the sum or average of a large random sample drawn with replacement will be roughly normal, regardless of the distribution of the population from which the sample is drawn. That’s a pretty big claim, but the theorem doesn’t stop there. It further states that the standard deviation of this normal distribution is given by sd of the original distribution psample size In other words, suppose we start with any distribution that has standard deviation x, take a sample of size n (where n is a large number) from that distribution with replacement, and compute the mean of that sample. If we repeat this procedure many times, then those sample means will have a normal distribution with standard deviation pxn. That’s an even bigger claim than the first one! The proof of the theorem is beyond the scope of this class, but in this exercise, we will be exploring some data to see the CLT in action. [Show More]
Last updated: 1 year ago
Preview 5 out of 32 pages

Loading document previews ...
Buy this document to get the full access instantly
Instant Download Access after purchase
Buy NowInstant download
We Accept:

Reviews( 0 )
$5.00
Can't find what you want? Try our AI powered Search
Document information
Connected school, study & course
About the document
Uploaded On
Oct 02, 2022
Number of pages
32
Written in
All

Additional information
This document has been written for:
Uploaded
Oct 02, 2022
Downloads
0
Views
118