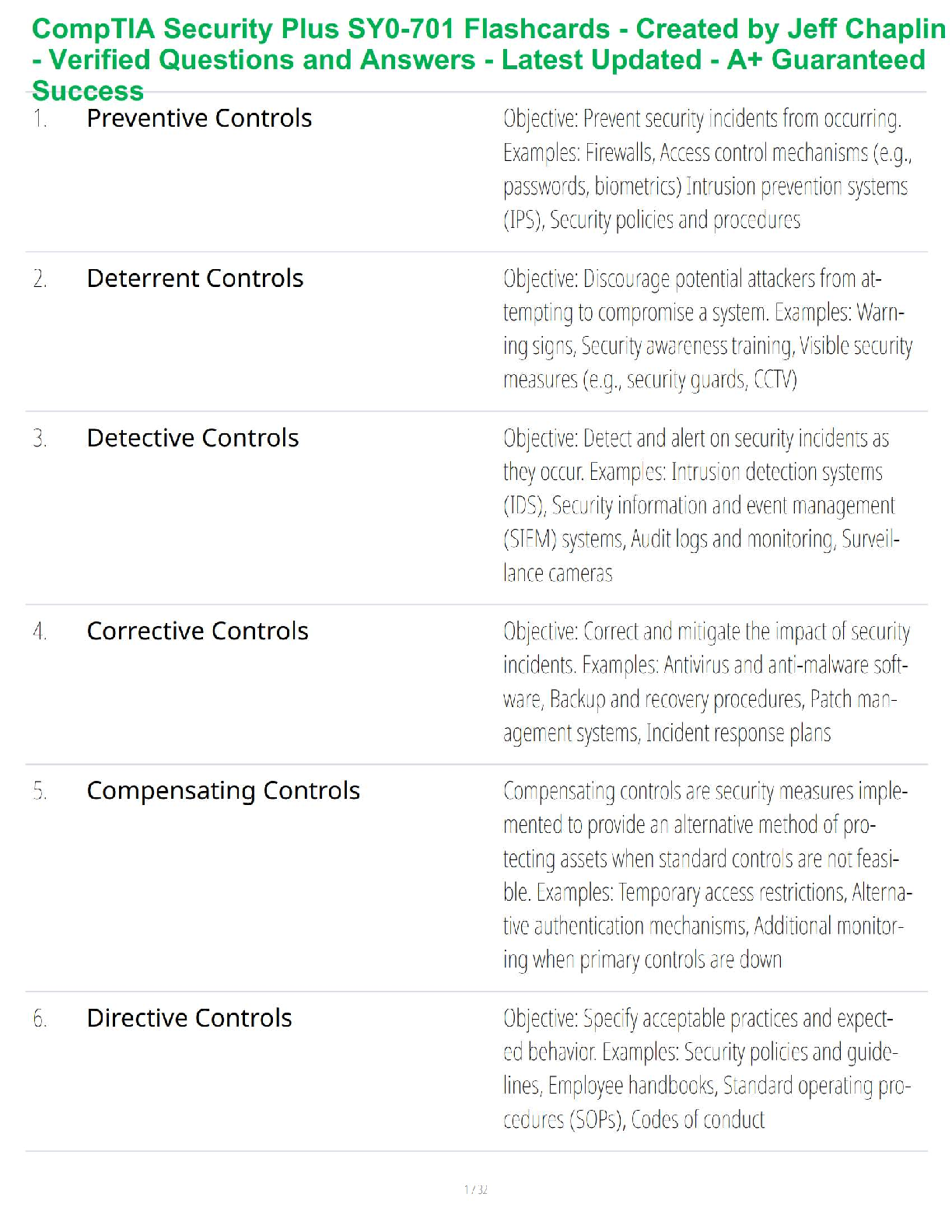
Revature Week 4 Review Questions
What is Hive? - ✔✔Hive is a tool that allows for SQL-Like querying on big data. Originally
built as a way to run MapReduce jobs by writing SQL, but has since changed (We're still using
...
Revature Week 4 Review Questions
What is Hive? - ✔✔Hive is a tool that allows for SQL-Like querying on big data. Originally
built as a way to run MapReduce jobs by writing SQL, but has since changed (We're still using
Hive on MapReduce jobs though)
Where is the default location of Hive's data in HDFS? - ✔✔o In the $HIVE_HOME directory.
o By default, all database and table data files are stored at /user/hive/warehouse
What is an External table? - ✔✔o Data kept outside of Hive that we query using Hive
What is a Managed table? - ✔✔o Data kept inside of Hive's internal data warehouse. This gives
safety + efficiency on the data since Hive controls it.
What is a Hive partition? - ✔✔o A Hive partition is a column of a table that we have split off
into a smaller dataset.
Provide an example of a good column or set of columns to partition on? - ✔✔o Time. We can
select an appropriate resolution to get reasonably sized partitions, it is easy to add new data, and
many queries subset time.
What's the benefit of partitioning? - ✔✔o Selecting the columns we have partitioned can lead to
increased performance.
What does a partitioned table look like in HDFS? - ✔✔o There will be one directory in the table
in HDFS per partition
What is a Hive bucket? - ✔✔o Bucketing is another tool to subset our data. It basically splits the
data equally into subsets, where each subset is reflective of the whole dataset.
What does it mean to have data skew and why does this matter when bucketing? - ✔✔o Data
skew is when our subsets have some non-uniform distribution. For example, if we bucket a table
based on continent, and we end up with one subset with only people from North America, it
would be skewed.
What does a bucketed table look like in HDFS? - ✔✔o It would look similar to partitioning,
except instead of multiple directories, we would get different files for each bucket.
What is the Hive metastore? - ✔✔o The metastore contains all the data for managed and external
tables. This includes columns, table names, database names, etc.
What is beeline? - ✔✔o Beeline is a JDBC (Java Database Connectivity) client that can be used
from the command line to interact with Hiveserver2 and run SQL-like queries.
How do you create a table? - ✔✔o CREATE TABLE student(
first_name STRING,
last_name STRING,
age INT,
state STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
TBLPROPERTIES("skip.header.line.count"="1");
How do you load data into a table? - ✔✔o LOAD DATA LOCAL INPATH
'/home/username/datafile' INTO TABLE
Note: data may or may not be local
How do you query data in a table? - ✔✔o SELECT














.png)