Electrical Engineering > QUESTIONS & ANSWERS > EECS 445 Introduction to Machine Learning Homework 4. | UNIVERSITY OF MICHIGAN Department of Electri (All)
EECS 445 Introduction to Machine Learning Homework 4. | UNIVERSITY OF MICHIGAN Department of Electrical Engineering and Computer Science
Document Content and Description Below
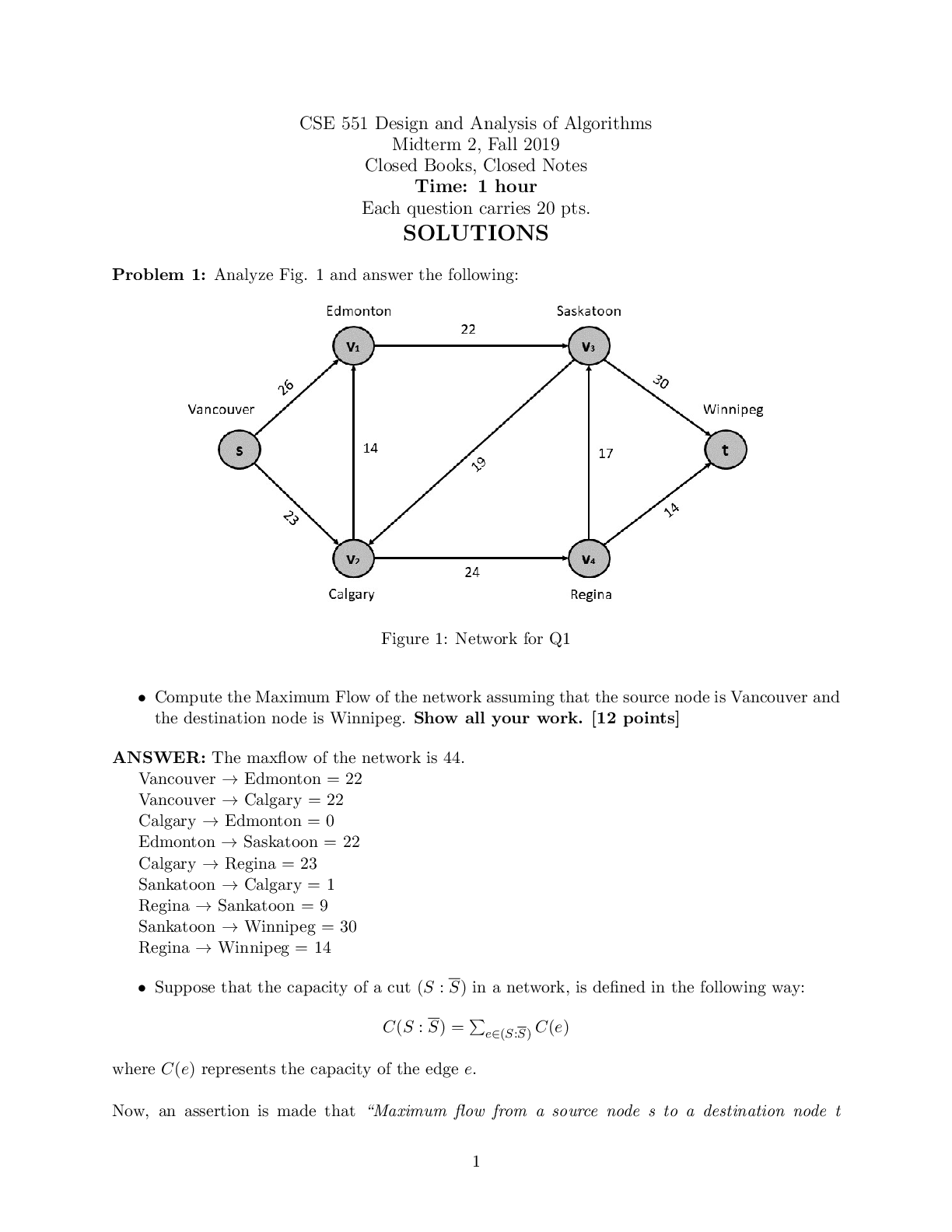
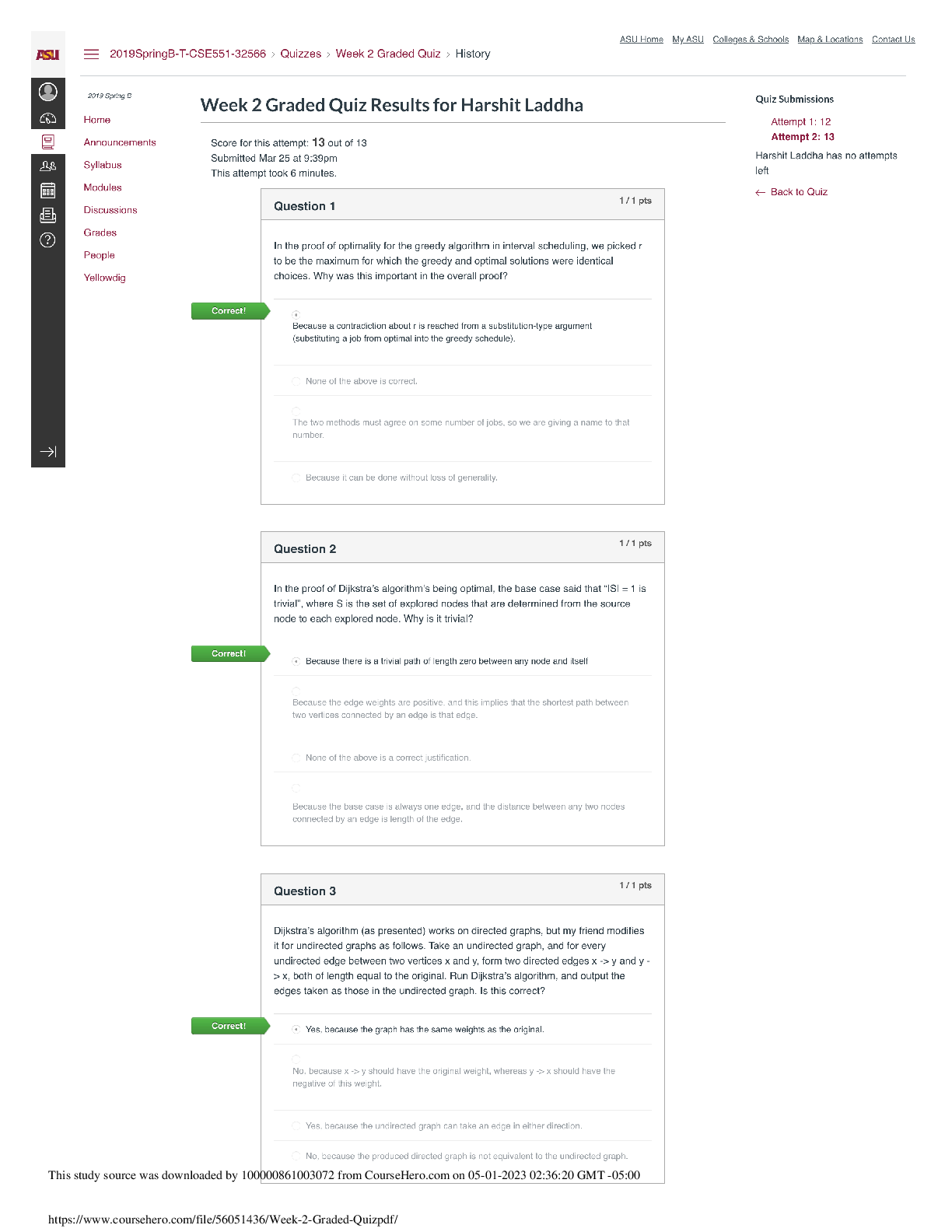
EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 1 UNIVERSITY OF MICHIGAN Department of Electrical Engineering and Computer Science EECS 445 Introduction to Machine Learning Winter ... 2019 Homework 4, Due: Tue. 04/16 at 11:59pm Submission: Please upload your completed assignment by 11:59pm ET on Tuesday, April 16 to Gradescope. Include all code as an appendix following your write-up. 1 Expectation Maximization [15 pts] Suppose we have three cities A, B and C each with a probability of having sunny weather, θA; θB and θC, unknown to us. To predict the weather of each city, we conduct an experiment. The experiment consists of N trials. For each trial, we choose one city from A, B and C uniformly at random, detect the weather of the chosen city over M days, and record the sequence of sunny / rainy. On the i-th trial, we define: • z(i) is the city chosen for this trial, z(i) 2 fA; B; Cg • x (i) j is the j-th detection for this trial, x( ji) 2 fS,Rg • si is the number of sunny days recorded on this trial. The data are generated as follows: for trial i 2 f1; : : : ; Ng : z(i) ∼ UniformfA; B; Cg for detection j 2 f1; : : : ; Mg : x (i) j ∼ Bernoulli(θz(i)), where θz(i) is the probability of sunny. 1.1 Complete-Data Case In this section, we consider the scenario in which we know both the resulting sequences and which city was chosen on each trial. (a) (2 pt) Write down an expression for the complete-data log-likelihood log p(¯ x(i); z(i); θ¯) of a single trial, in terms of si, M, and θz(i). EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 3 (c) (2 pt) Using the complete-data log-likelihood, derive expressions for the maximum-likelihood estimates of θA; θB and θC and report estimates of θA; θB and θC for the sample data. In words, describe what these estimates correspond to. EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 4 1.2 Classification-Maximization Now, assume the city indicators z(i) are unobserved (i.e., the city column in the table at the beginning of this problem is not available). That is, assume our experiment works as follows: you are a student stuck in BBB doing the 445 project. Your teammate decides to go to the three cities A, B and C with equal probability but he will not tell you which city he goes to. On each trial, he randomly chooses a city, detects its weather M times and records the sequence. The data are now “incomplete.” The Classification-Maximization algorithm estimates the model parameters by alternating between two steps: 1) Determining trial city assignment, 2) Maximizing likelihood. More precisely, it alternates between the following two steps after randomly initializing the parameters θ¯(0): C-step: Compute z^((ti+1) ) = arg max k2fA;B;Cg p(z(i) = k j x¯(i); θ¯(t)) for i = 1; : : : ; N (ties broken arbitrarily) M-step: Update θ¯(t+1) = arg max ¯ θ p(¯ x(i); z^((ti+1) ) ; θ¯) (maximum likelihood estimation given fixed city assignments) For this section, your task is to derive a Classification-Maximization procedure for the city detection experiment. EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 5 (a) (2 pt) Write down an expression for p(z(i) = k j x¯(i); θ¯(t)), the probability that trial i in city k 2 fA; B; Cg given the data x¯(i) and the current parameter estimate θ¯(t). Express your answer in terms of si, M and the model parameters θA(t); θB(t); θC(t). (b) (2 pt) Perform three iterations of Classification-Maximization for the sample data (either with code or by hand) and report your values of p(z(i) = k j x¯(i); θ¯(t)), z^((ti)), and θ¯(t) for each step. Initialize θ¯(0) = (0:7; 0:4; 0:6). In the case of a tie, choose the lexicographically smaller city, i.e., A < B < C. EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 6 EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 7 1.3 Expectation-Maximization As you may have noticed, Classification-Maximization struggles to make a decision when there is more than one plausible assignment for an observed sequence, and has no way of expressing the level of confidence in which city was chosen for a sequence. The Expectation-Maximization algorithm overcomes this limitation. Instead of using fixed assignments, it computes the probability p(z(i) = k j x¯(i); θ) that each point x¯(i) belongs to each distribution z(i) = k 2 fA; B; Cg. In discussion and in the above questions, we saw it was possible to write the complete-data log-likelihood with indicator variables that indicate which point belongs to which distribution. Now we can replace the indicator variables in the log-likelihood function with the probabilities above. This is analogous to going from hard-assignments to soft-assignments. In this case, the Expectation-Maximization algorithm repeats the following steps until convergence. E-Step. Evaluate p(z(i) = k j x¯(i); θ¯(t)) for each i = 1; : : : ; N and each k 2 fA; B; Cg M-Step. Update θ¯(t+1) = arg max ¯ θ PN i=1 Pk2fA;B;Cg p(z(i) = k j x¯(i); θ¯(t)) log 1 3(θk)si(1 - θk)M-si Now, you will derive an instance of the Expectation-Maximization algorithm for our city detection experiment. (a) (2 pt) Using the equations above, show that the updates for θk is as follows: θ(t+1) k = PN i=1 p(z(i) = k j x¯(i); θ(t)) × si M × PN i=1 p(z(i) = k j x¯(i); θ(t)) (b) (1 pt) Describe in words how the parameters above are updated; that is, what are these equations doing? Do they correspond to your intuition? 2 EM for Literary Creation [5 pts] As we saw above, the EM algorithm is a useful method for estimating the parameters of a distribution. How can we apply this algorithm to creating literature? Suppose we are interested in learning the underlying generative model for news articles. We hypothesize that each word in an article is generated based on the previous word. However, since we have limited data for estimating the model, we assume the current word is assigned to a cluster (denoted by z 2 f1; : : : ; kg), which then determines the next word. In other words, given wi (current word), we will generate wj (next word), according to: P (wjjwi) = kX z =1 P (wjjz)P (zjwi) = kX z =1 θ wjjzφzjwi where P (wjjz) = θwjjz and Pw2W θwjz = 1 for any cluster z = 1; :::; k. Similarly, P (zjwi) = φzjwi and Pk z=1 φzjwi = 1 for any current word wi 2 W. Here W denotes the set of possible words. This means that the probability of a word given the previous word is independent given cluster z. Our model is parameterized by two probability tables, θwjz and φzjw. (a) (2 pt) Suppose we observe w1 = “machine” (the current word) and w2 = “learning” (the next word). Derive an expression for the posterior probability of the current cluster z = 1 in terms of θ and φ given this information. EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 9 (b) (2 pt) We will use the EM algorithm to maximize the log-likelihood of generating the data. In our case, based on a sequence of words w1; :::; wT (i.e., an article), we aim to predict the underlying model generating the article. Derive an expression for the log-likelihood of words w2; :::; wT given w1 in terms of the parameters θ and φ. (c) (1 pt) In the EM algorithm, the M-step updates parameters θ and φ based on estimates of the posterior evaluated in the E-step. The M-step update for θ is: θ wjz = PT t=1 -1 p(zt = zjwt; wt+1)[[wt+1 == w]] Pw02W PT t=1 -1 p(zt = zjwt; wt+1)[[wt+1 == w0]] Explain how this equation updates θwjz in words. Does it correspond to your intuition? EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 10 3 Soft Clustering using GMM [7 pts] When fitting a model, adding more parameters can possibly increase the likelihood of data, but doing so may result in overfitting. In order to control the model size, we use the Bayesian Information Criteria (BIC): BIC = m ln N - 2 ln L^ where m is the number of independent parameters, N is the number of data points, and L^ is the maximized likelihood of data. We aim to minimize the BIC. For this problem, you will implement the EM algorithm for GMM and interpret the results. We will use the iris classification dataset, for which you may view details here: We have provided you with skeleton code including functions to access the data. You will need to modify gmm.py and run.py as noted in the comments with TODO tags. If you encounter an error claiming that the load iris() function was not found, please follow the instructions in 3.1 to update scikit-learn. Include answers to the following questions in your write-up. (a) (1 pt) Note that the code assumes all K Gaussians in the mixture to have a shared spherical diagonal covariance matrix σ2I. The likelihood of a point x¯ 2 Rd in this case is: p(¯ xjθ) = KX k =1 γkN(¯ x; ¯ µ(k); σ2I) Write down the number of independent parameters corresponding to the mixture model. (b) (3 pt) Implement the missing portions of gmm.py. The parts which you need to complete are the estimation functions for cluster probabilities for every point (zk matrix in code), GMM parameters and the Bayesian Information criteria (BIC). Here, zik is the probability that the ith data point belongs to cluster k. EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 11 You will use these update rules in your implementation in gmm.py. Note: You should first obtain the log-likelihood, and then obtain the likelihood/probability from that quantity. We encourage you to think about why it is that we might want to calculate likelihood in this way (this is more about issues with computers rather than with Machine Learning), but we won’t ask you for this explanation on the write up. Important implementation detail: Whenever you are taking the log of the sum of exponentials, you could run into issues due to the limited precision of computers. To obtain stable results, you should use the logsumexp trick. We imported the logsumexp function from the scipy package for you, which you should use to replace any log of the sum of exponentials. Refer to (c) (2 pt) In the run.py script, you have to train the GMM using integer values of hyperparameter k between 2 and 8 inclusive. Since EM is dependent on initialization, for each cluster size, you will have to run the gmm function multiple times to find the best BIC value which is achievable. While comparing results of various runs for each number of clusters, you’ll have to choose the best according to the BIC value. Explain (1) how you will compare two BIC values (lower vs. higher), and (2) how you will choose the clusters. Be sure to explain your reasoning for these choices. (d) (1 pt) Show the plot of the Bayesian Information Criteria (BIC) as a function of the number of clusters K. Describe the shape of the graph and write down your interpretation of the trend. Given this plot of BIC values, what is the number of clusters you’ll choose? Include the plot in your writeup as well. Note: Significant variation in this plot is expected due to the random initialization. EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 12 Figure 1: BIC Plot 3.1 Code Prerequisites • If you are currently using scikit-learn version 0.19.1 (or later), you should be sufficiently up-to-date. You can verify this by running conda list scikit-learn • If not, please run conda update scikit-learn to update EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 13 4 Bayesian Networks [5 pts] Instead of using HMM’s, we will be looking at an alternative Bayesian Network that tries to solve the same problem of hidden variables and observations. The network is as follows: Figure 2: Alternative to HMM (a) (2 pt) Check the following independence conditions of the graph: • Are X1, X2, and X3 all independent of each other given Z1 and Z2 (i.e., Xi j= XjjfZ1; Z2g for all i and j, where i 6= j)? • Is Z3 independent of Z1 given Z2? (b) (1 pt) Write down the factored joint probability distribution associated with the Bayesian Network described in part a. (c) (1 pt) If the random variables are all binary, how many parameters are there in the joint probability distribution implied by your graph? EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 14 (d) (1 pt) Suppose we learned the parameters for the above model, in addition to the parameters for an HMM (in which the Z’s represent hidden states, and the X’s represent observations). Applied to the training data both models achieve the same log-likelihood. Which model should we use? Briefly explain your answer. 5 Another Bayesian Network [3 pts] Consider the following Bayesian Network. Figure 3: Bayesian network for humidity EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 15 (a) (1 pt) Write down the factored joint probability distribution associated with this Bayesian Network. 6 Collaborative Filtering [10 pts] We can think of collaborative filtering as matrix factorization. Any n × m matrix X can be approximated by a lower rank matrix UV T where U is n × d and V is m × d and d ≤ minfm; ng. Let u¯(i) 2 Rd be the ith row vector of U and v¯(j) be the jth row vector of V . Then [UV T ]ij = ¯ u(i) · v¯(j). We want to use this low rank matrix to approximate observed binary labels in Y . Let Yij 2 f-1; 1g if the (i; j) entry is observed, and Yij = 0 otherwise. Then we would like to find U and V such that: Yij[UV T ]ij = Yij(¯ u(i) · v¯(j)) > 0 whenever Yij 6= 0 Note that this is trivially possible if X = UV T is full rank (each element can be chosen independently from each other). The smaller d we choose, the fewer adjustable parameters we have in U and V . Therefore, d controls the complexity of the solution that satisfies the constraints. It is often advantageous to potentially avoid satisfying all the constraints, e.g., if some of the labels may be mistakes. We might also suspect that we gain something by turning the estimation problem into a maximum margin problem, for u¯(i)’s given fv¯(j)g and for v¯(j)’s given fu¯(i)g. The formulation with slack is given by: subject to Yij(¯ u(i) · v¯(j)) ≥ 1 - ξij; ξij ≥ 0 for all (i; j) where Yij 6= 0 (a) (2 pt) If we fix U, i.e., fix all u¯(1); :::; u¯(n) the optimization problem reduces to m independent optimization problems. Define these optimization problems for v¯(j) where j = 1; :::; m. What do these optimization problems correspond to? EECS 445, Winter 2019 – Homework 4, Due: Tue. 04/16 at 11:59pm 16 (b) (1 pt) If we fix V , what does the optimization problem reduce to? (c) (1 pt) Suppose we have no observations in the ith row of Y . In other words, Yij = 0 for all j = 1; :::; m. If we fix U, will adding such an empty row affect what we get for v¯(j)? (d) (2 pt) Suppose there’s only one observation in the ith row. In other words, Yij = 1 for exactly one j (the rest are zeros). Assume no slack (C = 1). Solve for u¯(i) in terms of v¯(j) Note that the resulting u¯(i) specifies a maximum margin boundary through the origin. (Hint: try solving this geometrically.) (e) (4 pt) Consider a simple two-user and two-movie example and let the observed rating matrix and our initial guess for V be given by: Y = -1 0 1 1 V = 1 0 0 1 Assume no slack variables for this example. i. Solve by hand U^ = [¯ u(1); u¯(2)]T , given the initial V . Given this V and your solution U^, can you predict Y22? ii. Solve by hand V^ = [¯ v(1); v¯(2)]T , given your solution U^. Can you predict Y22 now? If so, what is the resulting prediction? REMEMBER to submit your completed assignment to Gradescope by 11:59pm ET on Tuesday, April 16. Include all code as an appendix following your write-up. [Show More]
Last updated: 8 months ago
Preview 3 out of 18 pages

Loading document previews ...
Buy this document to get the full access instantly
Instant Download Access after purchase
Buy NowInstant download
We Accept:

Reviews( 0 )
$7.00
Can't find what you want? Try our AI powered Search
Document information
Connected school, study & course
About the document
Uploaded On
Apr 18, 2023
Number of pages
18
Written in
All

Additional information
This document has been written for:
Uploaded
Apr 18, 2023
Downloads
0
Views
154