1 Markov Decision Process (10 Points)
You are in a Las Vegas casino! You have $20 for this casino venture and will play until you lose it all or as
soon as you double your money (i.e., increase your holding to at least
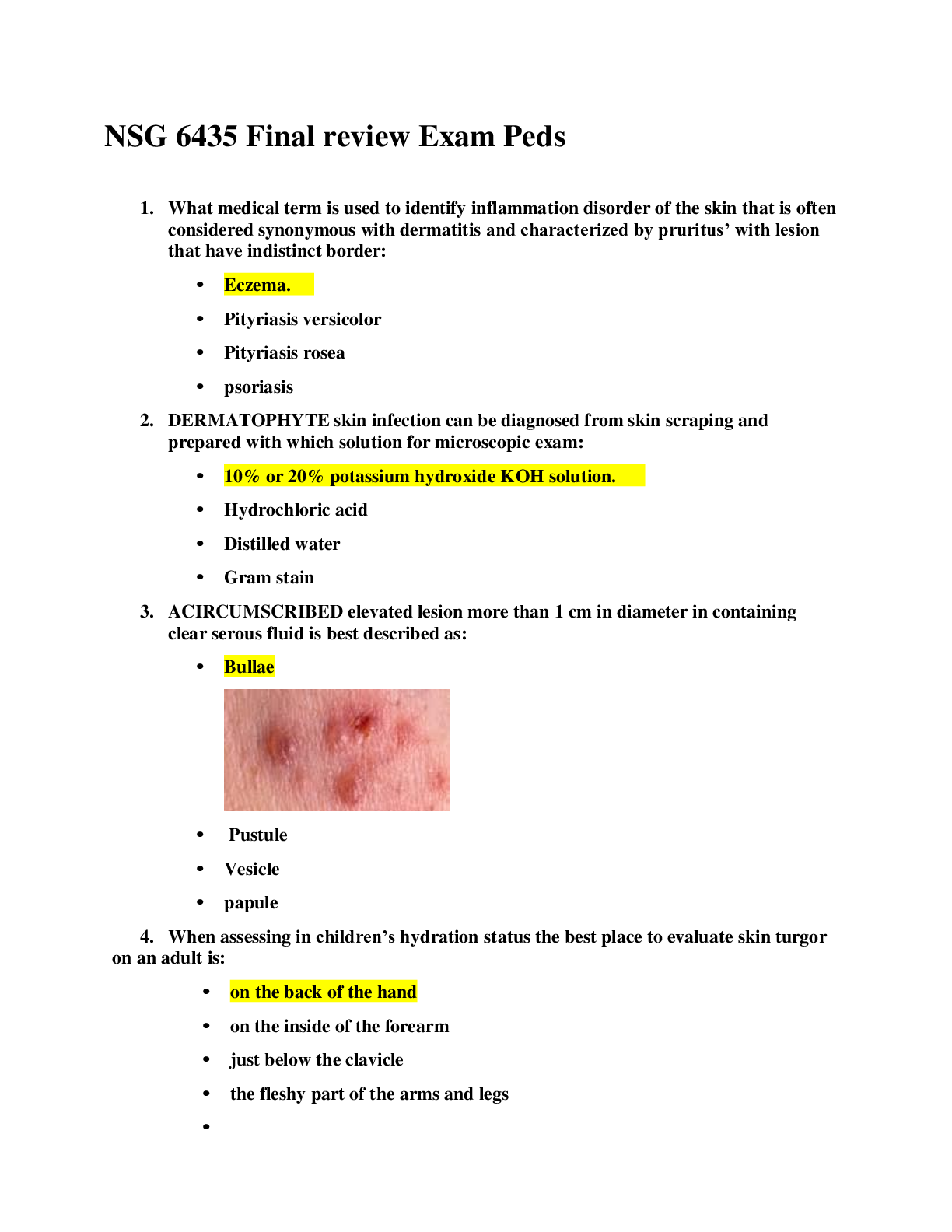
...
1 Markov Decision Process (10 Points)
You are in a Las Vegas casino! You have $20 for this casino venture and will play until you lose it all or as
soon as you double your money (i.e., increase your holding to at least $40). You can choose to play two slot
machines: 1) slot machine A costs $10 to play and will return $20 with probability 0:05 and $0 otherwise;
and 2) slot machine B costs $20 to play and will return $30 with probability 0:01 and $0 otherwise. Until
you are done, you will choose to play machine A or machine B in each turn. In the space below, provide
an MDP that captures the above description. Describe the state space, action space, rewards and transition
probabilities. Assume the discount factor γ = 1.
You can express your solution using equations instead of a table, or a diagram.
2 Bellman Operator with Function Approximation (12 Points)
Consider an MDP M = (S; A; R; P; γ) with finite discrete state space S and action space A. Assume M has
dynamics model P(s0js; a) for all s; s0 2 S and a 2 A and reward model R(s; a) for all s 2 S and a 2 A.
Recall that the Bellman operator B applied to a function V : S ! R is defined as
B(V )(s) = max
a
(R(s; a) + γ X
s0
P(s0js; a)V (s0))
(a) (4 Points) Now, consider a new operator which first applies a Bellman backup and then applies a
function approximation, to map the value function back to a space representable by the function
approximation. We will consider a linear value function approximator over a continuous state space.
Consider the following graphs:
The graphs show linear regression on the sample X0 = f0; 1; 2g for hypothetical underlying functions.
On the left, a target function f (solid line), that evaluates to f(0) = f(1) = f(2) = 0, and its
corresponding fitted function f^(x) = 0. On the right, another target function g (solid line), that
evaluates to g(0) = 0 and g(1) = g(2) = 1, and its fitted function ^ g(x) = 12 7 x.
What happens to the distance between points ff(0); f(1); f(2)g and fg(0); g(1); g(2)g after we do the
linear approximation? In other words, compare maxx2X0 jf(x) − g(x)j and maxx2X0 jf^(x) − g^(x)j.
(b) (4 Points) Is the linear function approximator here a contraction operator? Explain your answer.
(c) (4 Points) Will the new operator be guaranteed to converge to single value function? If yes, will this
be the optimal value function for the problem? Justify your answers.
3 Probably Approximately Correct (6 Points)
Let A(α; β) be a hypothetical reinforcement learning algorithm, parametrized in terms of α and β such that
for any α > β > 1, it selects action a for state s satisfying jQ(s; a) − V ∗(s)j ≤ αβ in all but N = jSjj 1−Aγjαβ
steps with probability at least 1 − β12 .
Per the definition of Probably Approximately Correct Reinforcement Learning, express N as a function
of jSj, jAj, δ, � and γ. What is the resulting N? Is algorithm A probably approximately correct (PAC)?
Briefly justify.
[Show More]









![Preview of eBook [PDF] Medicinal Chemistry for Practitioners By Jie Jack Li](https://browseimages.nyc3.digitaloceanspaces.com/paper-images/2026/04/29/pLwojgmw2026-04-29-08-1269f1932824861.png)