Data Mining > QUESTIONS & ANSWERS > MSMIT CSC550 Week1_hw Chapter 2_Problems. All Answers Provided. (All)
MSMIT CSC550 Week1_hw Chapter 2_Problems. All Answers Provided.
Document Content and Description Below
Last updated: 3 years ago
Preview 1 out of 3 pages
Instant download
.png)
Buy this Document to get the Full Access Instantly
Provided by Students Who Aced it
We Verify Document Content to Gurantee Accuracy
Reviews( 0 )
Document information
Connected school, study & course
About the document
Uploaded On
Sep 22, 2020
Number of pages
3
Written in
All

Additional information
This document has been written for:
Uploaded
Sep 22, 2020
Downloads
0
Views
268
Document Keyword Tags
Recommended For You
Get more on QUESTIONS & ANSWERS »

CSC550Z: Data Mining & Distributed Computing (Summer 2019) Wee...

MSMIT CSC550: Data Mining. Final Exam. 40 Questions and Answer...
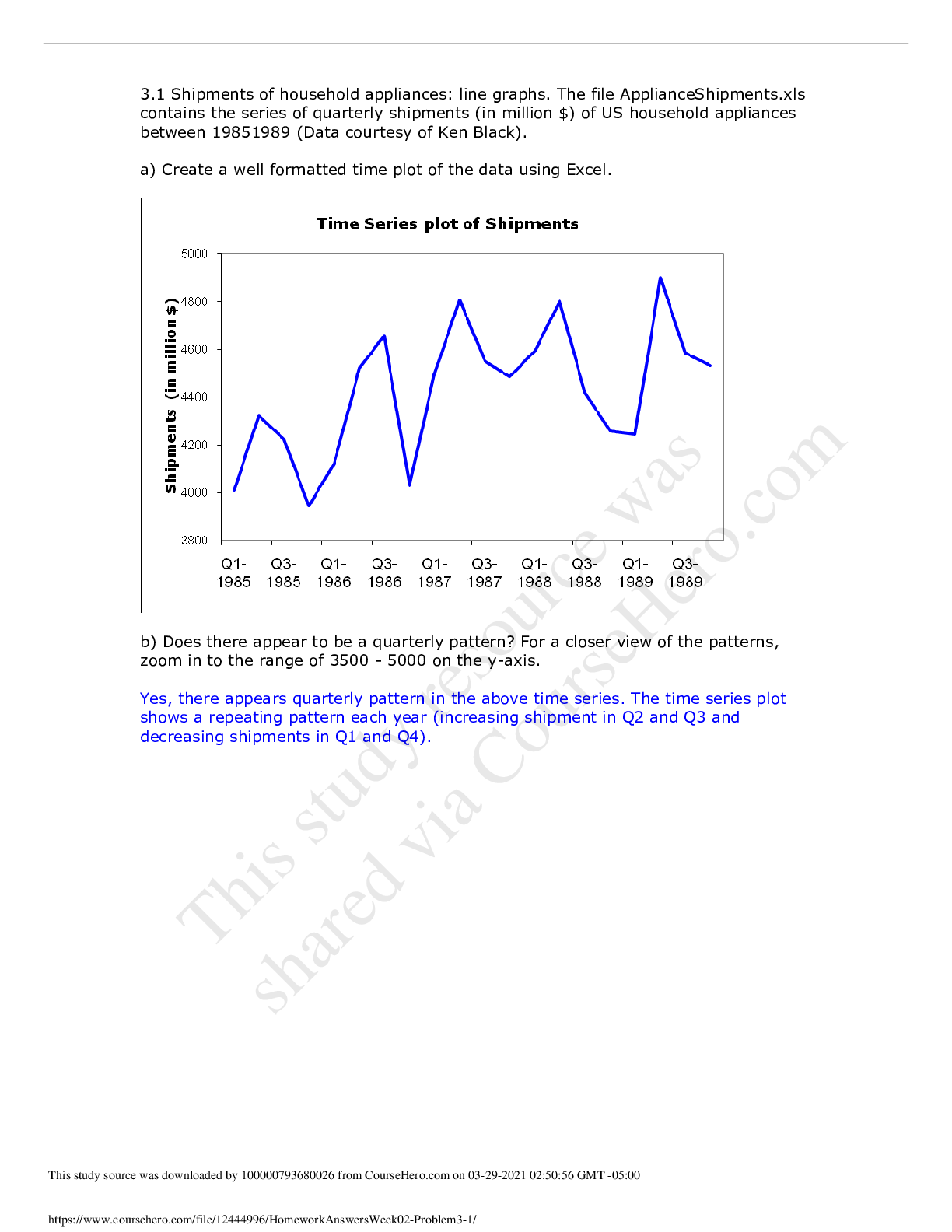
Sullivan University - MSMIT CSC550HomeworkAnswersWeek02_Proble...

Sullivan University - IT MANAGME CSC550XData_Mining_Assignment...


Test Bank for Lifespan Development in Context, A Topical Appro...

Test Bank for Introduction to Data Analytics for Accounting 1s...

ISYE 6501 Midterm Quiz 2 with all the Correct Answers(Graded A...

Georgia Institute Of Technology; ISYE 6501 Midterm Quiz 1 with...
ISYE 6501 Midterm Quiz 1 with all the Correct Answers(Graded A...

GT Students and Verified _ Midterm Quiz 1 with complete soluti...
.png)

Solutions Manual for Data Mining Concepts and Techniques 3rd E...

Solutions Manual for Data Mining Concepts and Techniques 3rd E...