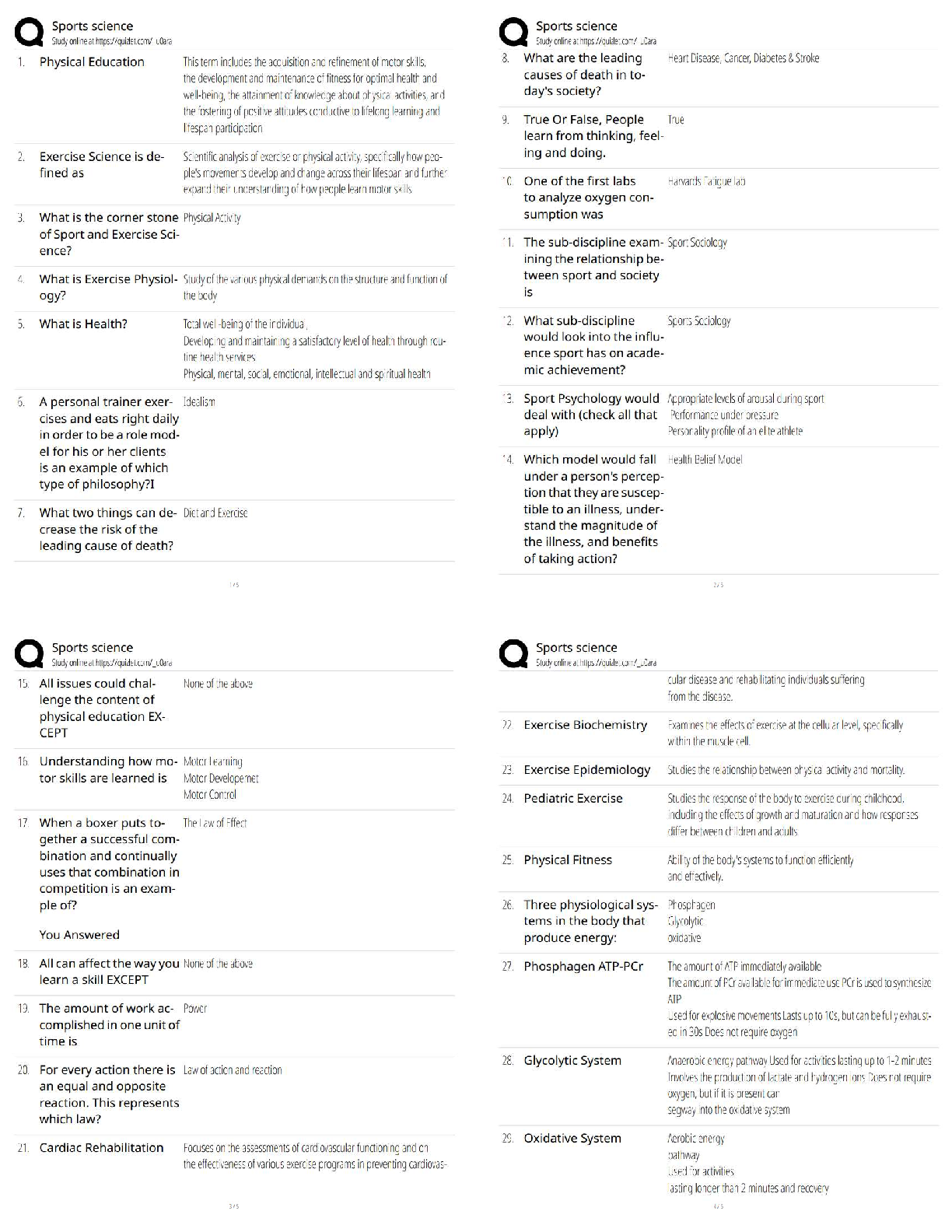
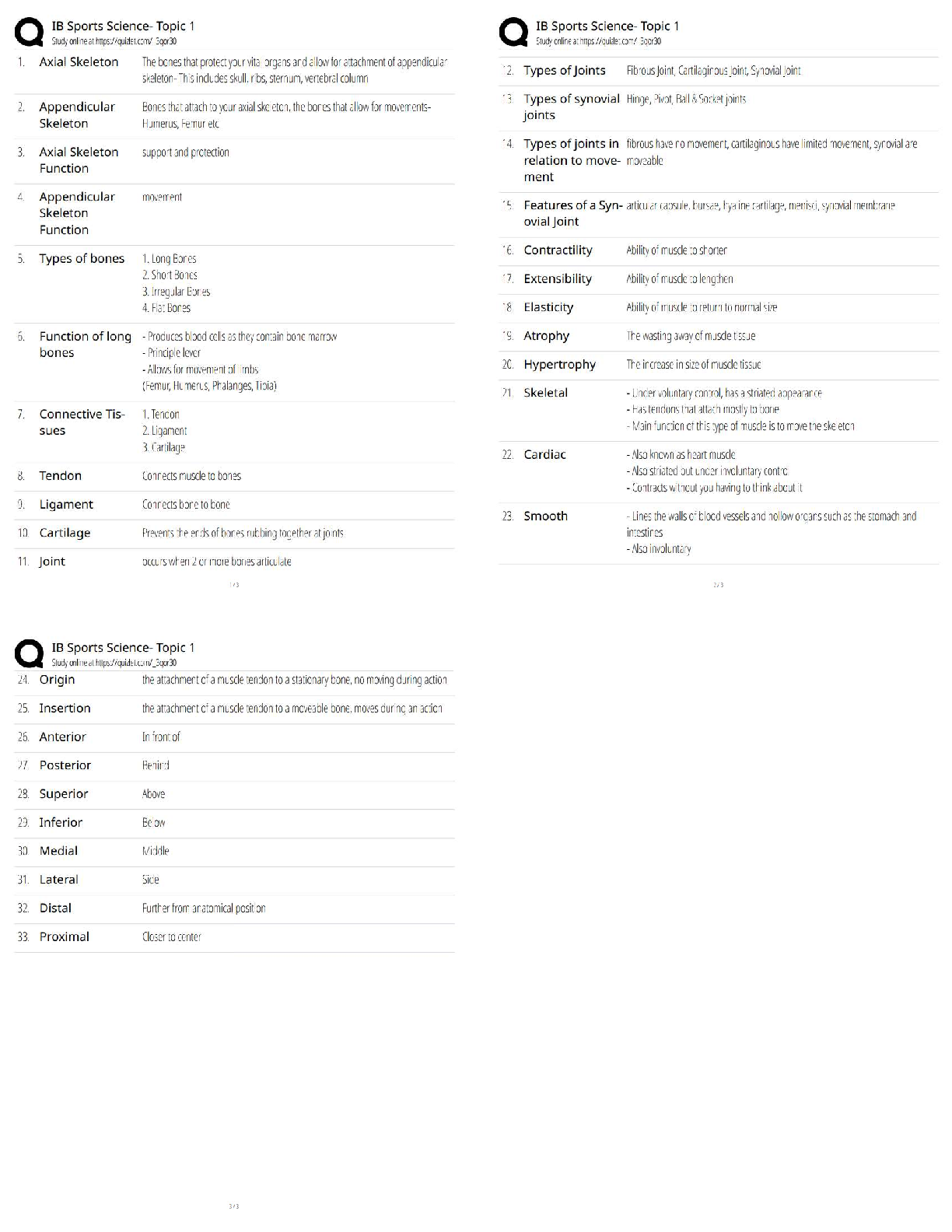
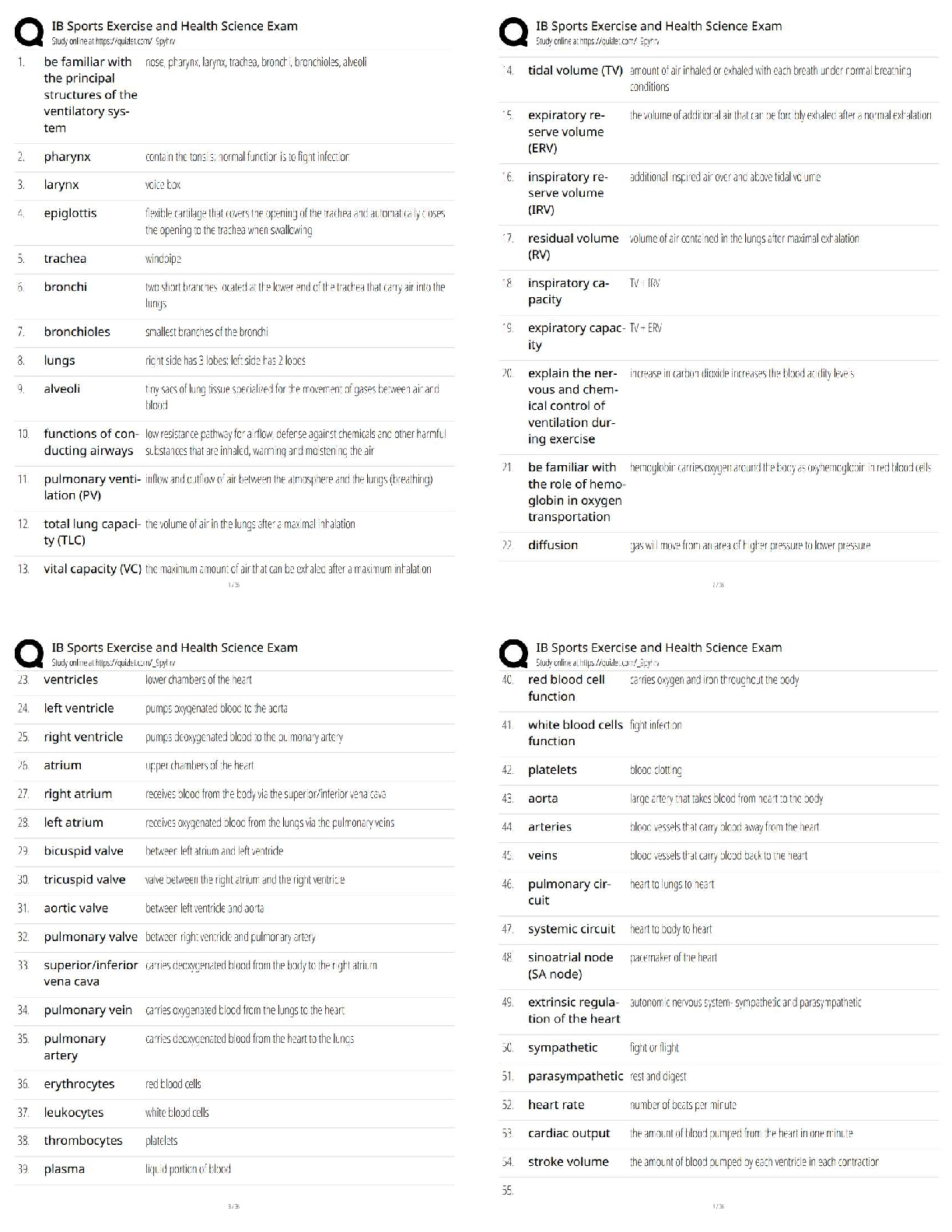
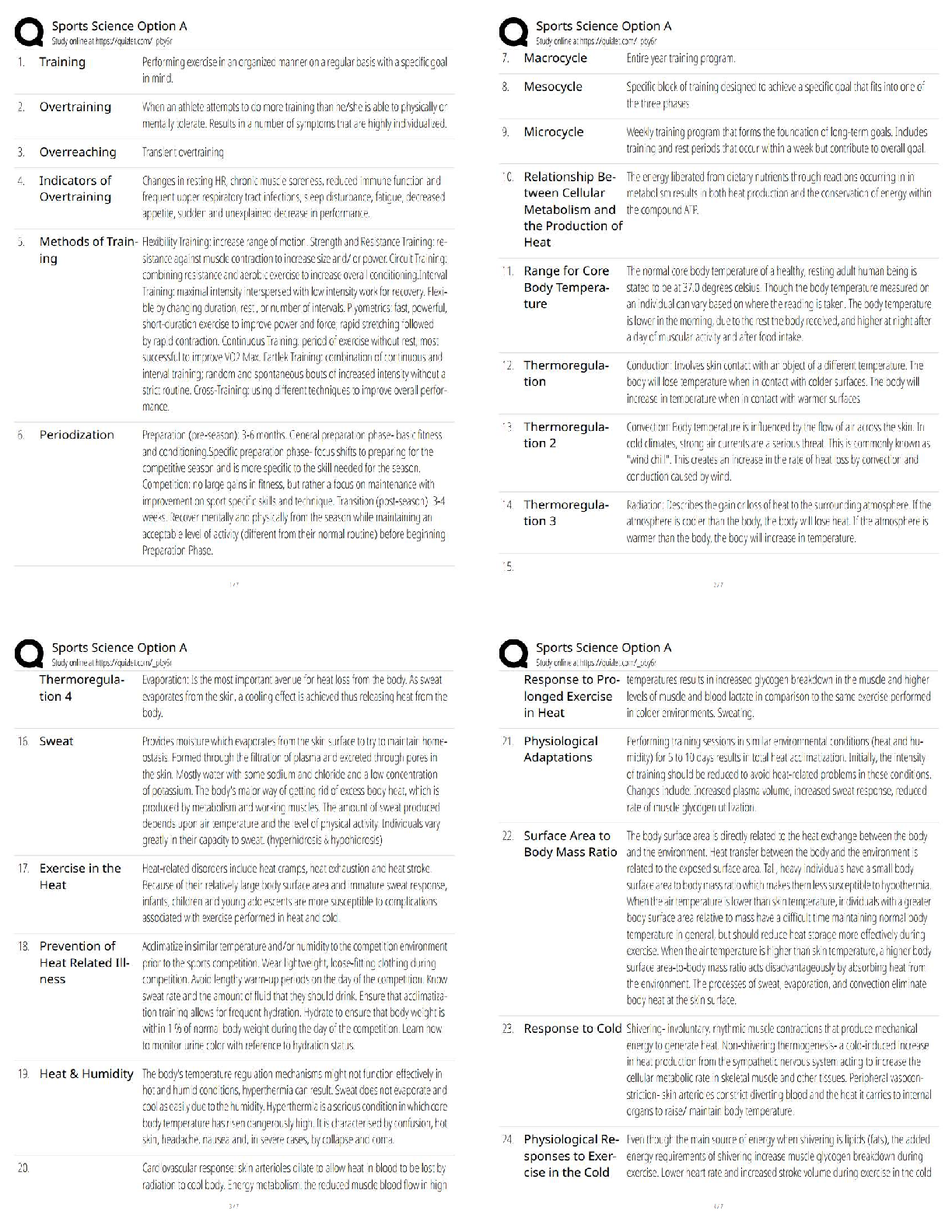
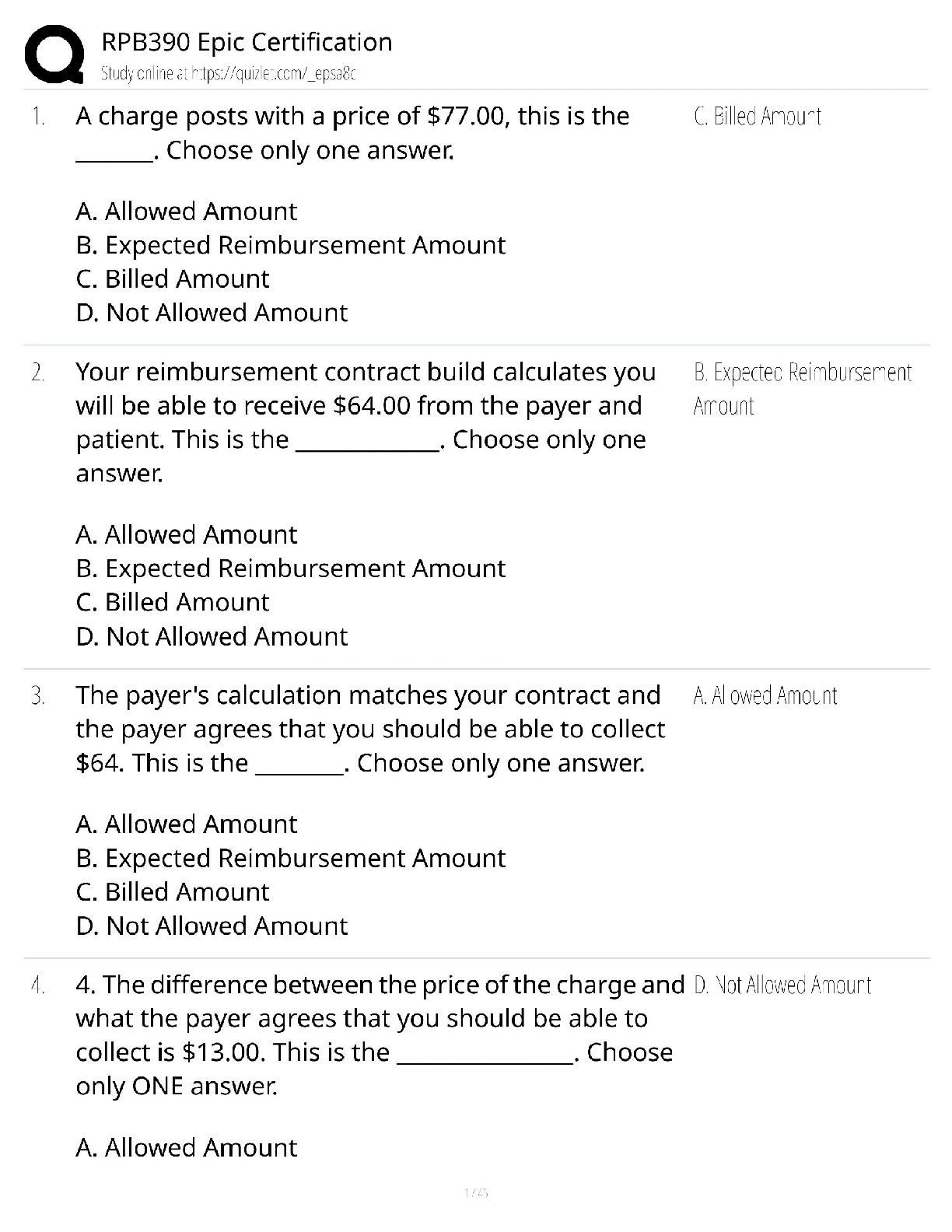
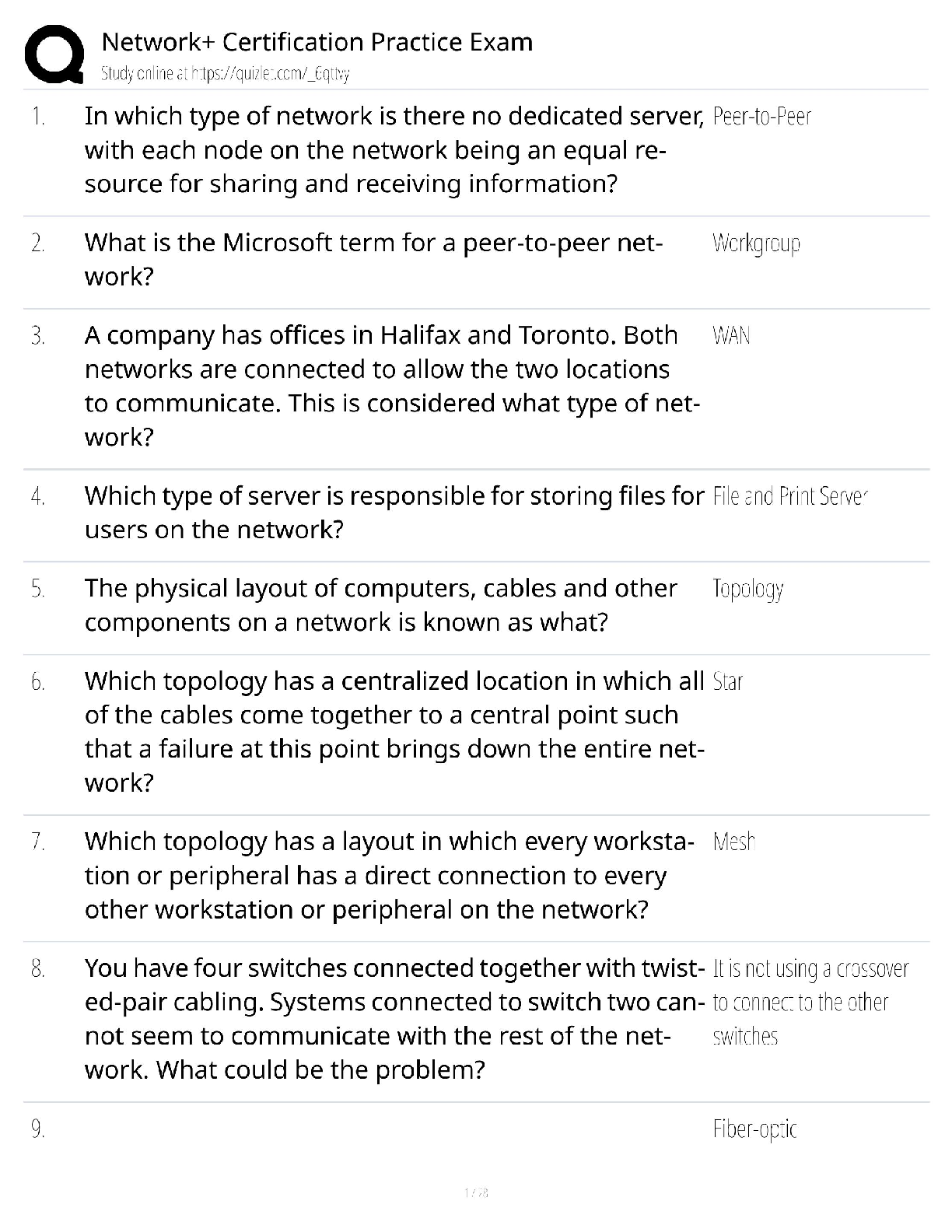
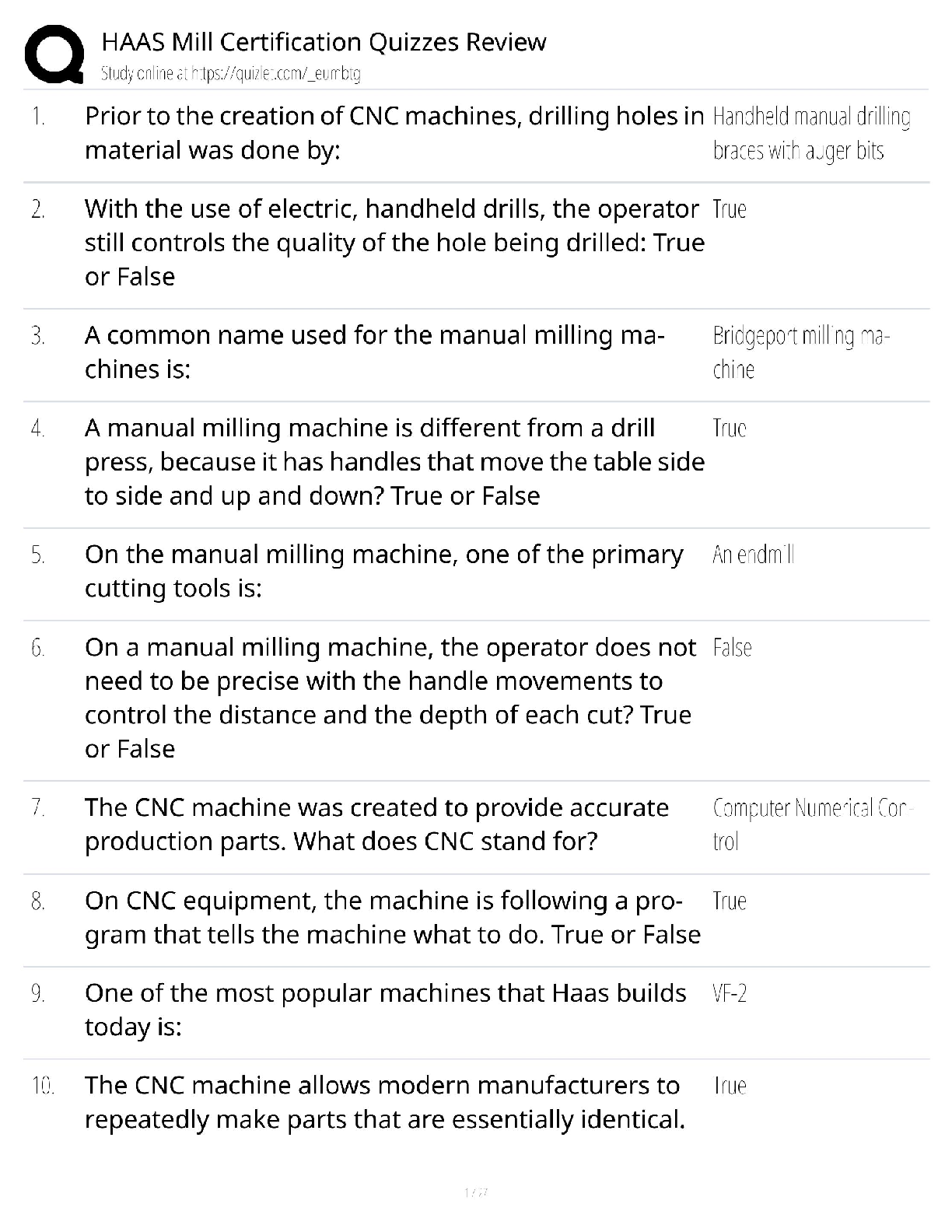
BACC 3119: Chapter 11. Most tested questions and quick read questions and answers for exam review.
Information Technology > QUESTIONS & ANSWERS > Georgia tech ISYE 6501: Introduction to Analytics Modeling Professor: Dr. Joel Sokol Homework 2. 100 (All)
ISYE 6501: Introduction to Analytics Modeling Professor: Dr. Joel Sokol Homework 2 24 January 2018 This study source was downloaded by 100000842525582 from CourseHero.com on 05-13-2022 05:33:43 GM ... T -05:00 https://www.coursehero.com/file/32154435/ISYE6501-Homework-2docx/Question 3.1 – Find a Good Classifier Using the same data set (credit_card_data.txt or credit_card_data-headers.txt) as in Question 2.2, use the ksvm or kknn function to find a good classifier: (a) Use the ksvm or kknn function to find a good classifier using cross-validation (do this for the knearest-neighbors model; SVM is optional) I compared three different k-nearest-neighbors models: 1. n fold cross validation with train.kknn = 88.99083% accuracy 2. k fold cross validation with cv.kknn = 82.4159% accuracy 3. k fold cross validation with caret library = 84.58633% accuracy I also explored different evaluators within train.kknn: 1. kernels explored: gaussian (best), rectangular, triangular, epanechnikov, rank, optimal 2. optimal k = 55 (had max set to 500, dialed down to 100 to speed things up) Specific results (optimal k, optimal kernel, etc) are included in the accompanying code. (b) Use the ksvm or kknn function to find a good classifier for splitting the data into training, validation, and test data sets (pick either KNN or SVM; the other is optional). I first explored different k values and kernels on data divided at 50% Training, 30% Validation, 20% Test sets. Then I adjusted the divisions to 60% Training, 30% Validation, 10% Test sets. Interestingly Gaussian and Triangular kernels both showed the same max accuracy for each of the data set divisions. 50%/30%/ 20% 60%/30%/ 10% kernel k value accuracy accuracy Gaussia n k = 10 0.847826 1 0.832460 7 Gaussia n k = 100 0.847826 1 0.811518 3 Triangul ar k = 2 0.788043 5 0.821989 5 Triangul ar k = 20 0.847826 1 0.832460 7 Triangul ar k = 200 0.847826 1 0.832460 7 Rectang ular k = 1 0.788043 5 0.821989 5 Rectang ular k = 10 0.836956 5 0.821989 5 Rectang ular k = 100 0.826087 0.811518 3 This study source was downloaded by 100000842525582 from CourseHero.com on 05-13-2022 05:33:43 GMT -05:00 https://www.coursehero.com/file/32154435/ISYE6501-Homework-2docx/Question 4.1 – Clustering Models Describe a situation or problem from your job, everyday life, current events, etc., for which a clustering model would be appropriate. List some (up to 5) predictors that you might use. Our company is exploring the use of on-demand and shared-space office facilities for our employees. This would help us shift our facility footprint from a few larger office buildings that may not align well to our operating model to numerous smaller facility spaces, presumably better aligned to operations. We are considering the following predictors: 1. Proximity to our clients a. Current clients b. Prospective and/or former clients 2. Proximity to our staff (zip codes) 3. Proximity to major airports and interstates 4. Facility cost ($/sf) [Show More]
Last updated: 3 years ago
Preview 1 out of 5 pages

Buy this document to get the full access instantly
Instant Download Access after purchase
Buy NowInstant download
We Accept:

GEORGIA TECH BUNDLE, ALL ISYE 6501 EXAMS, HOMEWORKS, QUESTIONS AND ANSWERS, NOTES AND SUMMARIIES, ALL YOU NEED
By bundleHub Solution guider 3 years ago
$60
59
Can't find what you want? Try our AI powered Search
Connected school, study & course
About the document
Uploaded On
Sep 03, 2022
Number of pages
5
Written in
All

This document has been written for:
Uploaded
Sep 03, 2022
Downloads
0
Views
162
Scholarfriends.com Online Platform by Browsegrades Inc. 651N South Broad St, Middletown DE. United States.
We're available through e-mail, Twitter, Facebook, and live chat.
FAQ
Questions? Leave a message!
Copyright © Scholarfriends · High quality services·